

blog

Una variabile casuale X è una variabile il cui valore dipende dall'esito di un fenomeno aleatorio cioè che si riferisce a un evento casuale. Ecco perché una variabile casuale è anche detta variabile aleatoria.
Una famiglia di variabili casuali dipendenti dal tempo, definite su uno spazio campione si definisce processo stocastico.
Un processo stocastico è un insieme di funzioni che evolvono nel tempo ognuna delle quali è associata ad un determinato elemento dello spazio campione, così che il risultato di un esperimento corrisponde all'estrazione di una di queste funzioni.

Supponi di avere uno spazio campionario contenente 4 studenti A, B, C, D. Se ora scegli casualmente lo studente A e misuri l'altezza in centimetri, puoi pensare alla variabile casuale X come alla funzione che probabilizza gli studenti in base alle loro altezze espresse mediante numeri reali.
A seconda di quale studente venga scelto casualmente la variabile X può assumere stati diversi o valori diversi in termini di altezza in centimetri.
Se la variabili casuali possono assumere solo un numero finito o numerabile infinito di valori distinti, allora sono variabili casuali discrete.
In altre parole, una variabile casuale è discreta se i valori che assume si possono contare e i numeri a cui fa riferimento sono i numeri naturali (0,1,2 ...).
I fenomeni che tipicamente si manifestano con numeri naturali sono per esempio tutti quelli che hanno a che fare con il conteggio delle persone:
oppure fenomeni per il conteggio di oggetti:
Insomma in generale caratteri in cui non possano comparire i decimali. Non posso studiare la probabilità di avere 15,7 studenti.
In questo articolo non voglio parlarti in modo approfondito di ogni singola variabile casuale. Ti metto però un elenco con i link agli articoli che parlano di alcune di esse e sotto un video esplicativo.
Modella un esperimento con due soli esiti possibili, successo (1) o insuccesso (0), con probabilità p di successo.

Descrive il numero di successi in n prove indipendenti di un esperimento di Bernoulli con probabilità p di successo in ogni prova.




Esercizio svolto sulla variabile casuale binomiale con la calcolatrice scientifica
Modella il numero di successi in n estrazioni senza reinserimento da una popolazione di N elementi, di cui k sono successi.


Variabile casuale ipergeometrica spiegata semplice con una metafora statistica

Esercizio svolto sulla variabile casuale ipergeometrica con la calcolatrice scientifica
É l'estensione della binomiale a tre possibili esiti per prova, con probabilità p1, p2, p3 tali che p1 + p2 + p3 = 1. Conta il numero di volte che ciascun esito si verifica in nnn prove.

Approssima il numero di eventi che si verificano in un intervallo di tempo o spazio, dati un tasso medio λ.



Esercizio svolto sulla variabile casuale Poisson con la calcolatrice scientifica
Modella il numero di prove Bernoulli necessarie per ottenere il primo successo.


É un'estensione la geometrica, modellando il numero di prove necessarie per ottenere r successi.


Assegna la stessa probabilità a ciascuno dei n valori possibili.

Se le variabili casuali possono assumere solo un numero infinito di valori, allora sono variabili casuali continue.
In altre parole, una variabile casuale è continua se i valori che assume si possono misurare e i numeri a cui fa riferimento sono i numeri reali (0 - 0,5 - 1 - 1,27 - 2,55 - …).
I fenomeni che tipicamente si manifestano con numeri reali sono per esempio tutti quelli che hanno a che fare con la misurazione delle persone:
oppure fenomeni per la misurazione di oggetti:
Insomma in generale caratteri in cui possano comparire i decimali, dove ovviamente sono inclusi anche i numeri naturali.
Ogni valore in un intervallo [a,b] ha la stessa probabilità.

Distribuzione simmetrica attorno alla media μ, con dispersione determinata da σ2.




Esercizio svolto sulla variabile casuale normale con la calcolatrice scientifica

Esercizio svolto sulla variabile casuale normale standardizzata con la calcolatrice scientifica
Modella una variabile il cui logaritmo segue una distribuzione normale.

Descrive il tempo tra eventi indipendenti con tasso λ.



Generalizza l’esponenziale e la chi-quadrato, con parametri k e θ.

Caso particolare della gamma con parametri k/2 e 2, utilizzata per test statistici.

Modella fenomeni economici e sociali con code pesanti, caratterizzata da una soglia minima xm e un parametro di forma α.

Utilizzata per piccoli campioni, con un parametro ν (gradi di libertà).

Modella il rapporto di due varianze campionarie, con parametri d1,d2 (gradi di libertà).

Definita su [0,1] con parametri di forma α e β, utile nell'inferenza Bayesiana.

Modella il tempo di vita di oggetti o sistemi, con parametri di forma k e scala λ.

Chiaramente una variabile aleatoria di per sé non ci fornisce informazioni sulla probabilità che questa assuma determinati valori.
Questa informazione viene fornita dalla distribuzione di probabilità della variabile aleatoria, ma a cosa si indica esattamente con questo termine? Di seguito rispondo a questa domanda e ti mostro come questo concetto è legato al calcolo delle probabilità.
La probabilità che una variabile casuale assuma uno dei suoi risultati possibili può essere data da una distribuzione di probabilità cioè da una funzione matematica che fornisce le probabilità di risultati diversi per un esperimento.
f: A —>p
Affinché la funzione di cui sopra caratterizzi una distribuzione di probabilità, deve seguire tutti gli assiomi di Kolmogorov:
La f(x) deve essere maggiore o uguale a 0. Non esiste al mondo una probabilità negativa, al massimo può essere nulla.
La f(x) deve essere minore o uguale a 1. Non esiste al mondo una probabilità che superi il tetto massimo del 100%.
Dai punti 1) e 2) si deduce che una probabilità deve sempre essere compresa tra 0 e 1, o se la vuoi vedere in termini percentuali tra lo 0% e il 100%.
Due eventi E1 e E2 sono incompatibili quando la loro l'intersezione forma un insieme vuoto ( E1 ⋂ E2 = Ø ), in altre parole il verificarsi di un evento esclude il verificarsi dell’altro.
Sotto questa ipotesi, si ha che la probabilità dell’unione dei due eventi è uguale alla somma delle probabilità dell’evento E1 e dell’evento E2. In formule questo si scrive come segue:
P ( E1 U E2 ) = P ( E1 ) + P ( E2 )
Tale formula si può estendere al caso con più di due eventi incompatibili
Il modo in cui descriviamo una distribuzione di probabilità e quindi la funzione suddetta dipende dal fatto che la variabile casuale sia discreta o continua.
Nel primo caso f si chiamerà funzione di massa di probabilità e si indicherà con p(x) mentre nel secondo caso sarà la funzione di densità di probabilità e si indicherà con f(x).
La funzione di massa di probabilità detta probability mass function in inglese (pmf) descrive la distribuzione di probabilità di variabili casuali discrete.
In altri termini, è una funzione che restituisce la probabilità che una variabile casuale sia esattamente uguale a un valore specifico, in formule:
p ( x ) = P( X = x )
N.B.
la X maiuscola indica il fenomeno, per esempio il numero di figli di una coppia.
la x minuscola indica i numeri che quel fenomeno può assumere, per esempio 0,1,2…
La probabilità restituita è sempre compresa nell'intervallo [0, 1] e la somma di tutte le probabilità per ogni stato è sempre uguale a uno.

Supponi che una famiglia vuole avere due figli e necessiti calcolare tutte le probabilità collegate alle possibili coppie di figli.
Forse non sai che c’è una legge matematica che si ripete sempre in qualsiasi paese del mondo, epoca o condizioni socio-culturali.
Nascono più uomini che donne!
Ebbene sì, su 1000 persone nate 515 saranno del genere maschile mentre 485 di quello femminile. Se non ci credi puoi controllare tu stesso sul sito demo.istat per riscontrare le nascite in Italia oppure guardarti il mio documentario sulla demografia italiana.

Tradotto in termini statistici puoi scrivere che P(M) = 0,515 infatti basta prendere i casi favorevoli (515) e dividerli per i casi possibili (1000).
Dunque i dati di partenza sono questi:
P(M) = numero maschi / numero totale nati = 515 / 1000 = 0,515
P(F) = numero femmine / numero totale nati = 485 / 1000 = 0,485
A questo punto devi identificare la tua variabile casuale. Può scegliere indifferentemente se farla in funzione dei maschi o delle femmine, tanto non cambia nulla.
Alla luce di ciò, scegliamo la la funzione “X: numero di maschi” su 2 figli nati:
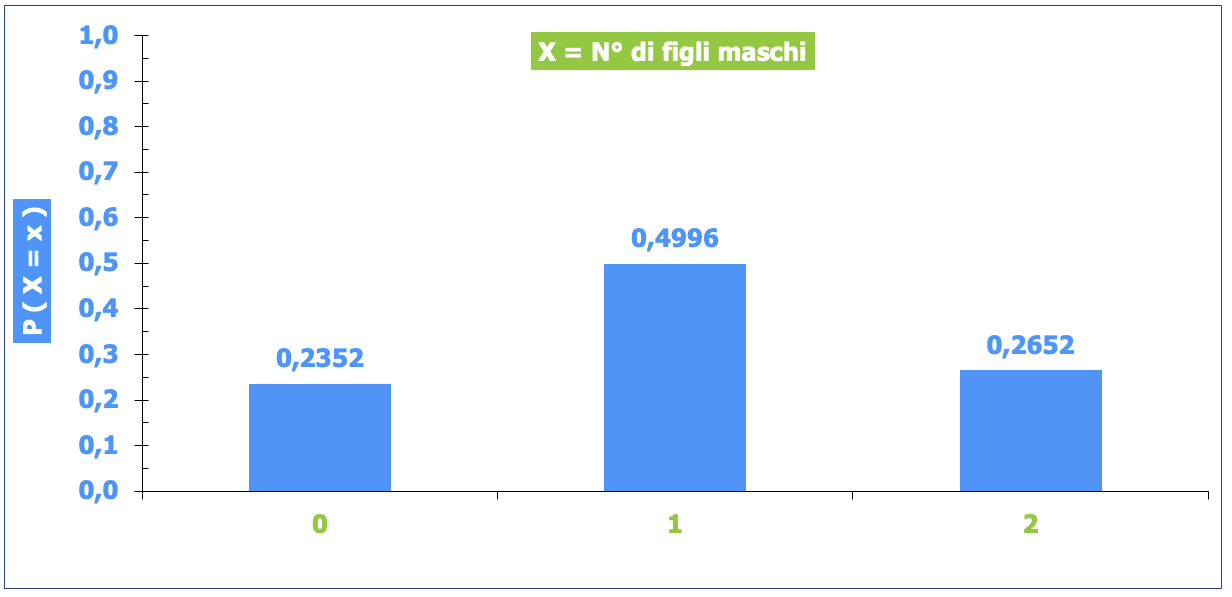
P (X = 0) = P (F-F) = 0,485 * 0,485 = 0,2352 (23,52%)
P (X = 1) = P (M-F) + P (F-M) = (0,515 * 0,485) * 2 = 0,4996 (49,96%)
P (X = 2) = P (M-M) = 0,515 * 0,515 = 0,2652 (26,52%)
Come vedi la probabilità di ottenere 0 maschi corrisponde al prodotto tra la probabilità di avere una femmina come primo e come secondo figlio. Analogo discorso per le altre probabilità
Di seguito il grafico della funzione di probabilità della VA.
Nel caso di variabili casuali continue, come già detto, la distribuzione di probabilità è fornita dalla funzione di densità (PDF).
Contrariamente alla funzione di massa (PMF), non fornisce la probabilità che una variabile casuale prenda direttamente uno stato specifico.
Descrive invece la probabilità che una variabile casuale si trovi all'interno di un particolare intervallo di valori. Tale probabilità non è altro che l’area che sta sotto la curva PDF e il suo calcolo richiede lo svolgimento di integrali matematici che vanno al di là dello scopo di questo articolo.
Per tale motivo, a titolo di esempio, qui sotto ti ho riportato il grafico della funzione di densità di una VA continua molto famosa: la variabile casuale normale. Ti rimando a questo articolo dove te ne ho parlato in dettaglio.

Legata alle PDF e PFM è la funzione di ripartizione F(x) detta abbreviatamente CDF. Questa è definita come la probabilità che la variabile casuale X assuma valore minore o uguale a uno specifico valore x fissato:
F ( x ) = P ( X <= x)
Nel caso di variabile aleatoria discreta sarà la somma di tutte le probabilità che vanno dal valore di X più piccolo fino al valore di X cercato.
Nel caso di variabile aleatoria continua sarà l’integrale che va dal valore di X più piccolo fino al valore di X cercato.
Tornando all’esempio dei figli se volessi calcolare la probabilità di avere al massimo 1 figlio maschio dovresti usare la funzione di ripartizione P(X ≤ 1) ovvero sommare le probabilità di P(X = 0) + P(X = 1) = 0,2352 + 0,4996 = 0,7348 (73,48%).
Non esiste un comando specifico, ma uno per ogni singola variabile. Le funzioni iniziano tutte con DISTRIB.
DISTRIB.NORM.N (x; media; dev_standard; cumulativa)
DISTRIB.NORM.ST.N (z; cumulativa)
DISTRIB.T.2T (x; grad_libertà)
DISTRIB.T.N (x; grad_libertà; code)
DISTRIB.T.DS (x; grad_libertà)
DISTRIB.LOGNORM.N (x; media; dev_standard; cumulativa)
DISTRIB.F.DS (x; grad_libertà1; grad_libertà2)
DISTRIBF (x; grad_libertà1; grad_libertà2; cumulativa)
DISTRIB.BINOM.N (num_successi; prove; probabilità_s; cumulativa)
DISTRIB.IPERGEOM.N (s_campione; num_campione; s_pop; num_pop; cumulativa)
DISTRIB.BINOM.NEG.N (num_insuccessi; num_successi; probabilità_s; cumulativa)
DISTRIB.POISSON (x; media; cumulativa)
DISTRIB.EXP.N (x; lambda; cumulativa)
DISTRIB.GAMMA.N (x; alfa; beta; cumulativa)
DISTRIB.CHI.QUAD (x; grad_libertà; cumulativa)
DISTRIB.CHI.QUAD.DS (x; grad_libertà)
DISTRIB.BETA.N (x; alfa; beta; cumulativa; a; b)
DISTRIB.WEIBULL (x; alfa; beta; cumulativa)
Non esiste un comando specifico
Le teorie statistiche nascondono un perfetto deciso e una realtà constatata dietro variabili che eludono le nostre tecniche sperimentali.
(LOUIS DE BROGLIE)
Iscriviti alla Newsletter