

blog

La cluster analysis, detta anche analisi dei cluster o dei gruppi in italiano, è una tecnica di data analysis multivariata, che permette di suddividere le osservazioni in gruppi omogenei, ciascuno dei quali contiene unità statistiche simili tra loro.
Un cluster è, appunto, un sottoinsieme di osservazioni (le righe di un dataset) delle variabili analizzate (le colonne del dataset) che contiene caratteristiche simili.

La cluster analysis è una tecnica statistica diversa dalle altre, perché si basa sull’apprendimento non supervisionato, cioè consente di raggruppare un insieme di oggetti senza poter sfruttare esempi da utilizzare come base di apprendimento.
Continuando a leggere comprenderai non solo come condurre la cluster analysis, ma conoscerai anche i diversi algoritmi di clustering che i principali software statistici come SPSS ed R includono.
Questo tipo di analisi possono essere utilizzate per accorpare osservazioni simili delle variabili coinvolte nello stesso cluster. Viene utilizzata in svariati campi per rispondere a diverse ipotesi di ricerca:
Medicina - Quali sono i cluster diagnostici? Questo è il caso in cui si predispone un dataset che include i possibili sintomi come ansia, depressione, stanchezza, ecc. I cluster che si formano sono rappresentati dai gruppi di pazienti che hanno sintomi simili.
Marketing - Quali sono i customer segments? Le variabili coinvolte hanno a che fare con gli aspetti demografici, i bisogni, le abitudini e i comportamenti dei clienti. In questo caso i cluster sono formati dai soggetti che presentano gli stessi atteggiamenti.
Istruzione - Quali sono gli studenti che hanno bisogno di particolare attenzione? La cluster analysis identifica i gruppi di studenti omogenei, cioè quelli che si assomigliano ad esempio in termini di voti scolastici, velocità d’apprendimento e attitudine allo studio.
Biologia - Qual è la tassonomia delle specie? Immagina di avere un dataset contenente diverse specie di piante, con differenti attributi dei loro fenotipi. Allora, con cluster analysis si può costruire la tassonomia di gruppi e sottogruppi di piante aventi gli stessi attributi.
Prima di iniziare a scoprire tutte le caratteristiche di questa tecnica statistica avanzata, ti lascio il video di presentazione del mio video corso sulla cluster analysis.

Nel caso della cluster analysis, per suddividere il dataset in gruppi si possono utilizzare sia variabili numeriche che categoriali, o includere entrambi i tipi.
Nel mio video corso sull'analisi delle componenti principali e sulla cluster analysis presento tre tipi di clusterizzazione: gerarchica, non gerarchica, two-step. In questo articolo ti presento i primi due.
Una volta scelte le variabili, a questo punto devi scegliere quale metrica utilizzare per calcolare la distanza tra le varie unità statistiche.
Infatti, l’appartenenza di due elementi a un stesso gruppo dipende da quanto sono vicini: minore è la distanza tra essi, maggiore è la probabilità che appartengono allo stesso cluster.
Per calcolare quanto un'osservazione, che molto spesso è una persona, è vicina a un'altra ci sono diversi indici. Di seguito ti elenco le formule delle distanze più conosciute e ti mostro degli esempi sulla base di questi dati.
Tabella dei dati:
\[
\begin{array}{|c|c|c|c|c|c|}
\hline
\scriptsize{Unità} & \scriptsize{V1} & \scriptsize{V2} & \scriptsize{V3} & \scriptsize{V4} & \scriptsize{V5} \\
\hline
\scriptsize{1} & \scriptsize{8} & \scriptsize{8} & \scriptsize{9} & \scriptsize{9} & \scriptsize{8} \\
\scriptsize{2} & \scriptsize{4} & \scriptsize{4} & \scriptsize{5} & \scriptsize{4} & \scriptsize{4} \\
\scriptsize{3} & \scriptsize{8} & \scriptsize{7} & \scriptsize{7} & \scriptsize{8} & \scriptsize{7} \\
\scriptsize{4} & \scriptsize{5} & \scriptsize{6} & \scriptsize{6} & \scriptsize{6} & \scriptsize{6} \\
\scriptsize{5} & \scriptsize{6} & \scriptsize{6} & \scriptsize{6} & \scriptsize{6} & \scriptsize{7} \\
\scriptsize{6} & \scriptsize{3} & \scriptsize{4} & \scriptsize{4} & \scriptsize{5} & \scriptsize{4} \\
\hline
\end{array}
\]
La distanza Euclidea è la formula della distanza più utilizzata per calcolare lo spazio tra due punti del piano cartesiano ed è calcolata come la radice quadrata della somma dei quadrati delle differenze delle loro coordinate.
Formula della distanza euclidea:
\[
d(\mathbf{X}, \mathbf{Y}) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}
\]
dove:
\[
\mathbf{X} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}
\quad \text{e} \quad
\mathbf{Y} =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix}
\]
sono due vettori di \( n \) dimensioni, e \( d(\mathbf{X}, \mathbf{Y}) \) è la distanza tra di essi.
Calcolo delle distanze Euclidee:
Per calcolare la distanza tra due unità \(i\) e \(j\), dobbiamo applicare la formula sopra alla differenza tra i valori delle variabili corrispondenti. Ecco le distanze tra ogni coppia di unità.
\[
\begin{array}{|c|l|}
\hline
\scriptsize{Coppie} & \scriptsize{Distanza Euclidea} \\
\hline
\scriptsize{(1, 2)} & \scriptsize{\sqrt{(8-4)^2 + (8-4)^2 + (9-5)^2 + (9-4)^2 + (8-4)^2}} \\
& \scriptsize{= \sqrt{16 + 16 + 16 + 25 + 16}} \\
& \scriptsize{= \sqrt{89} \approx 9.43} \\
\hline
\scriptsize{(1, 3)} & \scriptsize{\sqrt{(8-8)^2 + (8-7)^2 + (9-7)^2 + (9-8)^2 + (8-7)^2}} \\
& \scriptsize{= \sqrt{0 + 1 + 4 + 1 + 1}} \\
& \scriptsize{= \sqrt{7} \approx 2.65} \\
\hline
\scriptsize{(1, 4)} & \scriptsize{\sqrt{(8-5)^2 + (8-6)^2 + (9-6)^2 + (9-6)^2 + (8-6)^2}} \\
& \scriptsize{= \sqrt{9 + 4 + 9 + 9 + 4}} \\
& \scriptsize{= \sqrt{35} \approx 5.92} \\
\hline
\scriptsize{(1, 5)} & \scriptsize{\sqrt{(8-6)^2 + (8-6)^2 + (9-6)^2 + (9-6)^2 + (8-7)^2}} \\
& \scriptsize{= \sqrt{4 + 4 + 9 + 9 + 1}} \\
& \scriptsize{= \sqrt{27} \approx 5.19} \\
\hline
\scriptsize{(1, 6)} & \scriptsize{\sqrt{(8-3)^2 + (8-4)^2 + (9-4)^2 + (9-5)^2 + (8-4)^2}} \\
& \scriptsize{= \sqrt{25 + 16 + 25 + 16 + 16}} \\
& \scriptsize{= \sqrt{98} \approx 9.90} \\
\hline
\end{array}
\]
Tabella riepilogativa delle distanze Euclidee:
\[
\begin{array}{|c|c|c|c|c|c|c|}
\hline
\scriptsize{\textbf{Unità}} & \scriptsize{\textbf{1}} & \scriptsize{\textbf{2}} & \scriptsize{\textbf{3}} & \scriptsize{\textbf{4}} & \scriptsize{\textbf{5}} & \scriptsize{\textbf{6}} \\
\hline
\scriptsize{1} & & \scriptsize{9,43} & \scriptsize{2,65} & \scriptsize{5,92} & \scriptsize{5,20} & \scriptsize{9,90} \\
\scriptsize{2} & & & \scriptsize{7,35} & \scriptsize{3,74} & \scriptsize{4,69} & \scriptsize{1,73} \\
\scriptsize{3} & & & & \scriptsize{4,00} & \scriptsize{3,16} & \scriptsize{7,81} \\
\scriptsize{4} & & & & & \scriptsize{1,41} & \scriptsize{4,12} \\
\scriptsize{5} & & & & & & \scriptsize{5,20} \\
\scriptsize{6} & & & & & & \\
\hline
\end{array}
\]
E' la stessa formula della precedente solo che non si applica la radice quadrata. Di solito è la più utilizzata nel processo di cluster analysis.
Formula della distanza Euclidea al quadrato:
\[
d^2(\mathbf{X}, \mathbf{Y}) = \sum_{i=1}^{n} (x_i - y_i)^2
\]
dove:
\[
\mathbf{X} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}
\quad \text{e} \quad
\mathbf{Y} =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix}
\]
sono due vettori di \( n \) dimensioni, e \( d^2(\mathbf{X}, \mathbf{Y}) \) è la distanza al quadrato tra di essi.
Calcolo delle distanze Euclidee al quadrato:
Per calcolare la distanza Euclidea al quadrato tra due unità \(i\) e \(j\), sommiamo i quadrati delle differenze tra i valori corrispondenti delle variabili. Ecco le distanze tra ogni coppia di unità.
\[
\begin{array}{|c|l|}
\hline
\scriptsize{Coppie} & \scriptsize{Distanza Euclidea al quadrato} \\
\hline
\scriptsize{(1, 2)} & \scriptsize{(8-4)^2 + (8-4)^2 + (9-5)^2 + (9-4)^2 + (8-4)^2} \\
& \scriptsize{= 16 + 16 + 16 + 25 + 16} \\
& \scriptsize{= 89} \\
\hline
\scriptsize{(1, 3)} & \scriptsize{(8-8)^2 + (8-7)^2 + (9-7)^2 + (9-8)^2 + (8-7)^2} \\
& \scriptsize{= 0 + 1 + 4 + 1 + 1} \\
& \scriptsize{= 7} \\
\hline
\scriptsize{(1, 4)} & \scriptsize{(8-5)^2 + (8-6)^2 + (9-6)^2 + (9-6)^2 + (8-6)^2} \\
& \scriptsize{= 9 + 4 + 9 + 9 + 4} \\
& \scriptsize{= 35} \\
\hline
\scriptsize{(1, 5)} & \scriptsize{(8-6)^2 + (8-6)^2 + (9-6)^2 + (9-6)^2 + (8-7)^2} \\
& \scriptsize{= 4 + 4 + 9 + 9 + 1} \\
& \scriptsize{= 27} \\
\hline
\scriptsize{(1, 6)} & \scriptsize{(8-3)^2 + (8-4)^2 + (9-4)^2 + (9-5)^2 + (8-4)^2} \\
& \scriptsize{= 25 + 16 + 25 + 16 + 16} \\
& \scriptsize{= 98} \\
\hline
\end{array}
\]
Tabella riepilogativa delle distanze Euclidee al quadrato:
\[
\begin{array}{|c|c|c|c|c|c|c|}
\hline
\scriptsize{\textbf{Unità}} & \scriptsize{\textbf{1}} & \scriptsize{\textbf{2}} & \scriptsize{\textbf{3}} & \scriptsize{\textbf{4}} & \scriptsize{\textbf{5}} & \scriptsize{\textbf{6}} \\
\hline
\scriptsize{1} & & \scriptsize{89} & \scriptsize{7} & \scriptsize{35} & \scriptsize{27} & \scriptsize{98} \\
\scriptsize{2} & & & \scriptsize{54} & \scriptsize{14} & \scriptsize{22} & \scriptsize{3} \\
\scriptsize{3} & & & & \scriptsize{16} & \scriptsize{10} & \scriptsize{61} \\
\scriptsize{4} & & & & & \scriptsize{2} & \scriptsize{17} \\
\scriptsize{5} & & & & & & \scriptsize{27} \\
\scriptsize{6} & & & & & & \\
\hline
\end{array}
\]
È la somma delle differenze assolute tra le coordinate di due punti, come se si dovesse percorrere solo su una griglia ortogonale.
Formula della distanza di Manhattan:
\[
d(\mathbf{X}, \mathbf{Y}) = \sum_{i=1}^{n} |x_i - y_i|
\]
dove:
\[
\mathbf{X} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}
\quad \text{e} \quad
\mathbf{Y} =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix}
\]
sono due vettori di \( n \) dimensioni, e \( d(\mathbf{X}, \mathbf{Y}) \) è la distanza tra di essi.
Calcolo delle distanze di Manhattan:
Per calcolare la distanza tra due unità \(i\) e \(j\), dobbiamo applicare la formula sopra alla differenza assoluta tra i valori delle variabili corrispondenti. Ecco le distanze tra ogni coppia di unità.
\[
\begin{array}{|c|l|}
\hline
\scriptsize{Coppie} & \scriptsize{Distanza di Manhattan} \\
\hline
\scriptsize{(1, 2)} & \scriptsize{|8-4| + |8-4| + |9-5| + |9-4| + |8-4|} \\
& \scriptsize{= 4 + 4 + 4 + 5 + 4} \\
& \scriptsize{= 21} \\
\hline
\scriptsize{(1, 3)} & \scriptsize{|8-8| + |8-7| + |9-7| + |9-8| + |8-7|} \\
& \scriptsize{= 0 + 1 + 2 + 1 + 1} \\
& \scriptsize{= 5} \\
\hline
\scriptsize{(1, 4)} & \scriptsize{|8-5| + |8-6| + |9-6| + |9-6| + |8-6|} \\
& \scriptsize{= 3 + 2 + 3 + 3 + 2} \\
& \scriptsize{= 13} \\
\hline
\scriptsize{(1, 5)} & \scriptsize{|8-6| + |8-6| + |9-6| + |9-6| + |8-7|} \\
& \scriptsize{= 2 + 2 + 3 + 3 + 1} \\
& \scriptsize{= 11} \\
\hline
\scriptsize{(1, 6)} & \scriptsize{|8-3| + |8-4| + |9-4| + |9-5| + |8-4|} \\
& \scriptsize{= 5 + 4 + 5 + 4 + 4} \\
& \scriptsize{= 22} \\
\hline
\end{array}
\]
Tabella riepilogativa delle distanze di Manhattan:
\[
\begin{array}{|c|c|c|c|c|c|c|}
\hline
\scriptsize{\textbf{Unità}} & \scriptsize{\textbf{1}} & \scriptsize{\textbf{2}} & \scriptsize{\textbf{3}} & \scriptsize{\textbf{4}} & \scriptsize{\textbf{5}} & \scriptsize{\textbf{6}} \\
\hline
\scriptsize{1} & & \scriptsize{21} & \scriptsize{5} & \scriptsize{13} & \scriptsize{11} & \scriptsize{22} \\
\scriptsize{2} & & & \scriptsize{13} & \scriptsize{9} & \scriptsize{11} & \scriptsize{6} \\
\scriptsize{3} & & & & \scriptsize{8} & \scriptsize{5} & \scriptsize{15} \\
\scriptsize{4} & & & & & \scriptsize{3} & \scriptsize{7} \\
\scriptsize{5} & & & & & & \scriptsize{8} \\
\scriptsize{6} & & & & & & \\
\hline
\end{array}
\]
È una misura di distanza che tiene conto delle correlazioni tra le variabili, normalizzando la distanza Euclidea per la matrice di covarianza dei dati.
Formula della distanza di Mahalanobis:
\[
d(\mathbf{X}, \mathbf{Y}) = \sqrt{ (\mathbf{X} - \mathbf{Y})^T S^{-1} (\mathbf{X} - \mathbf{Y}) }
\]
dove:
\[
\mathbf{X} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}
\quad \text{e} \quad
\mathbf{Y} =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix}
\]
sono due vettori di \( n \) dimensioni, \( S^{-1} \) è la matrice inversa della matrice di covarianza \( S \), e \( d(\mathbf{X}, \mathbf{Y}) \) è la distanza tra di essi.
Calcolo delle distanze di Mahalanobis:
Per calcolare la distanza tra due unità \(i\) e \(j\), dobbiamo applicare la formula sopra tenendo conto della matrice di covarianza delle variabili. Ecco le distanze tra ogni coppia di unità.
\[
\begin{array}{|c|l|}
\hline
\scriptsize{Coppie} & \scriptsize{Distanza di Mahalanobis} \\
\hline
\scriptsize{(1, 2)} & \scriptsize{\sqrt{ (\mathbf{X_1} - \mathbf{X_2})^T S^{-1} (\mathbf{X_1} - \mathbf{X_2}) }} \\
& \scriptsize{= \sqrt{ (4,4,4,5,4) S^{-1} (4,4,4,5,4)^T }} \\
& \scriptsize{= 4.67} \\
\hline
\scriptsize{(1, 3)} & \scriptsize{\sqrt{ (\mathbf{X_1} - \mathbf{X_3})^T S^{-1} (\mathbf{X_1} - \mathbf{X_3}) }} \\
& \scriptsize{= \sqrt{ (0,1,2,1,1) S^{-1} (0,1,2,1,1)^T }} \\
& \scriptsize{= 1.56} \\
\hline
\scriptsize{(1, 4)} & \scriptsize{\sqrt{ (\mathbf{X_1} - \mathbf{X_4})^T S^{-1} (\mathbf{X_1} - \mathbf{X_4}) }} \\
& \scriptsize{= \sqrt{ (3,2,3,3,2) S^{-1} (3,2,3,3,2)^T }} \\
& \scriptsize{= 3.89} \\
\hline
\scriptsize{(1, 5)} & \scriptsize{\sqrt{ (\mathbf{X_1} - \mathbf{X_5})^T S^{-1} (\mathbf{X_1} - \mathbf{X_5}) }} \\
& \scriptsize{= \sqrt{ (2,2,3,3,1) S^{-1} (2,2,3,3,1)^T }} \\
& \scriptsize{= 3.12} \\
\hline
\scriptsize{(1, 6)} & \scriptsize{\sqrt{ (\mathbf{X_1} - \mathbf{X_6})^T S^{-1} (\mathbf{X_1} - \mathbf{X_6}) }} \\
& \scriptsize{= \sqrt{ (5,4,5,4,4) S^{-1} (5,4,5,4,4)^T }} \\
& \scriptsize{= 5.03} \\
\hline
\end{array}
\]
Tabella riepilogativa delle distanze di Mahalanobis:
\[
\begin{array}{|c|c|c|c|c|c|c|}
\hline
\scriptsize{\textbf{Unità}} & \scriptsize{\textbf{1}} & \scriptsize{\textbf{2}} & \scriptsize{\textbf{3}} & \scriptsize{\textbf{4}} & \scriptsize{\textbf{5}} & \scriptsize{\textbf{6}} \\
\hline
\scriptsize{1} & & \scriptsize{4.67} & \scriptsize{1.56} & \scriptsize{3.89} & \scriptsize{3.12} & \scriptsize{5.03} \\
\scriptsize{2} & & & \scriptsize{3.41} & \scriptsize{2.78} & \scriptsize{2.95} & \scriptsize{1.97} \\
\scriptsize{3} & & & & \scriptsize{2.01} & \scriptsize{1.73} & \scriptsize{3.58} \\
\scriptsize{4} & & & & & \scriptsize{1.12} & \scriptsize{2.67} \\
\scriptsize{5} & & & & & & \scriptsize{2.89} \\
\scriptsize{6} & & & & & & \\
\hline
\end{array}
\]
Misura la differenza tra due stringhe (o vettori) dello stesso formato, contando il numero di posizioni in cui i valori sono diversi. Adatta a variabili binarie o categoriali, la distanza di Hamming è usata soprattutto nell’ambito informatico, per calcolare la differenza tra due stringhe di bit.
Formula della distanza di Hamming:
\[
d(\mathbf{X}, \mathbf{Y}) = \sum_{i=1}^{n} \mathbb{1}(x_i \neq y_i)
\]
dove:
\[
\mathbf{X} =
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}
\quad \text{e} \quad
\mathbf{Y} =
\begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{bmatrix}
\]
sono due vettori di \( n \) dimensioni, e \( d(\mathbf{X}, \mathbf{Y}) \) è la distanza tra di essi. La funzione indicatrice \( \mathbb{1}(x_i \neq y_i) \) assume valore 1 se \( x_i \neq y_i \), altrimenti assume valore 0.
Calcolo delle distanze di Hamming:
Per calcolare la distanza di Hamming tra due unità \(i\) e \(j\), contiamo il numero di posizioni in cui i valori corrispondenti sono diversi. Ecco le distanze tra ogni coppia di unità.
\[
\begin{array}{|c|l|}
\hline
\scriptsize{Coppie} & \scriptsize{Distanza di Hamming} \\
\hline
\scriptsize{(1, 2)} & \scriptsize{\mathbb{1}(8 \neq 4) + \mathbb{1}(8 \neq 4) + \mathbb{1}(9 \neq 5) + \mathbb{1}(9 \neq 4) + \mathbb{1}(8 \neq 4)} \\
& \scriptsize{= 1 + 1 + 1 + 1 + 1} \\
& \scriptsize{= 5} \\
\hline
\scriptsize{(1, 3)} & \scriptsize{\mathbb{1}(8 \neq 8) + \mathbb{1}(8 \neq 7) + \mathbb{1}(9 \neq 7) + \mathbb{1}(9 \neq 8) + \mathbb{1}(8 \neq 7)} \\
& \scriptsize{= 0 + 1 + 1 + 1 + 1} \\
& \scriptsize{= 4} \\
\hline
\scriptsize{(1, 4)} & \scriptsize{\mathbb{1}(8 \neq 5) + \mathbb{1}(8 \neq 6) + \mathbb{1}(9 \neq 6) + \mathbb{1}(9 \neq 6) + \mathbb{1}(8 \neq 6)} \\
& \scriptsize{= 1 + 1 + 1 + 1 + 1} \\
& \scriptsize{= 5} \\
\hline
\scriptsize{(1, 5)} & \scriptsize{\mathbb{1}(8 \neq 6) + \mathbb{1}(8 \neq 6) + \mathbb{1}(9 \neq 6) + \mathbb{1}(9 \neq 6) + \mathbb{1}(8 \neq 7)} \\
& \scriptsize{= 1 + 1 + 1 + 1 + 1} \\
& \scriptsize{= 5} \\
\hline
\scriptsize{(1, 6)} & \scriptsize{\mathbb{1}(8 \neq 3) + \mathbb{1}(8 \neq 4) + \mathbb{1}(9 \neq 4) + \mathbb{1}(9 \neq 5) + \mathbb{1}(8 \neq 4)} \\
& \scriptsize{= 1 + 1 + 1 + 1 + 1} \\
& \scriptsize{= 5} \\
\hline
\end{array}
\]
Tabella riepilogativa delle distanze di Hamming:
\[
\begin{array}{|c|c|c|c|c|c|c|}
\hline
\scriptsize{\textbf{Unità}} & \scriptsize{\textbf{1}} & \scriptsize{\textbf{2}} & \scriptsize{\textbf{3}} & \scriptsize{\textbf{4}} & \scriptsize{\textbf{5}} & \scriptsize{\textbf{6}} \\
\hline
\scriptsize{1} & & \scriptsize{5} & \scriptsize{4} & \scriptsize{5} & \scriptsize{5} & \scriptsize{5} \\
\scriptsize{2} & & & \scriptsize{4} & \scriptsize{4} & \scriptsize{5} & \scriptsize{3} \\
\scriptsize{3} & & & & \scriptsize{4} & \scriptsize{3} & \scriptsize{4} \\
\scriptsize{4} & & & & & \scriptsize{2} & \scriptsize{4} \\
\scriptsize{5} & & & & & & \scriptsize{3} \\
\scriptsize{6} & & & & & & \\
\hline
\end{array}
\]
La cluster analysis gerarchica, adatta solo alle variabili quantitative e qualitative dicotomiche, prevede che i gruppi siano annidati e organizzati come un albero gerarchico.
Tale gerarchia è visibile mediante la rappresentazione di un grafico chiamato dendrogramma che permette di capire il numero di cluster ideale da scegliere.
A seconda del criterio di similarità che si sceglie, secondo cui due unità statistiche si considerano simili e quindi appartenenti allo stesso gruppo, il cluster gerarchico può essere di due tipi: aggregativo e divisivo.
In questo caso si inizia considerando le singole unità statistiche per poi aggregarle nei gruppi. Tale approccio è anche noto come bottom-up, ossia dal basso verso l’alto.
L’aggregazione tra gruppi può essere effettuata valutando le distanze cluster-to-cluster, cioè le misure che riguardano due gruppi. Se si opera con la matrice delle distanze (calcolata con una delle distanze viste precedentemente), questa fornisce già la distanza cluster-to-cluster al primissimo livello.
Per fondere gruppi con diversa cardinalità occorre definire il legame (o link) secondo cui esprimere la dissomiglianza che due cluster possono avere. Di seguito ti descrivo i vari tipi di metodi di aggregazione più popolari.
Tra tutte le possibili unioni tra due gruppi si sceglie quella con varianza entro i gruppi minima e quella varianza tra i gruppi massima.
Adatto per gruppi che hanno forma sferica e distribuzione normale multivariata, mentre non lo è quando i gruppi hanno diversa forma e numerosità. Tecnica molto efficiente che tende a produrre gruppi di eguale numerosità e di piccole dimensioni. E' uno dei metodi più utilizzati all'interno della cluster analysis.
In SPSS viene chiamato metodo di Ward.
La distanza o dissimilarità tra due cluster coincide con la distanza minima tra due entità di cui una nel primo gruppo e lʼaltro nel secondo.
Va incontro alla criticità del concatenamento (chaining). La peculiarità risiede nel fatto di creare gruppi esigui, concatenati, che assumono una forma allungata. Crea dei concatenamenti artificiali tra i cluster maggiori e favorisce la cannibalizzazione di quelli più piccoli. Robusto nei confronti degli outliers.
In SPSS viene chiamato vicino più vicino.
La distanza o dissimilarità tra due cluster coincide con la distanza massima tra due entità di cui una nel primo cluster e lʼaltro nel secondo.
Produce gruppi armonici e compatti con una notevole omogeneità interna, e risulta particolarmente appropriata nei casi in cui gli elementi formano realmente blocchi naturali e distinti.
Forma cluster di tipo sferico anche se di questi non vi è traccia nei dati. Non robusto nei confronti degli outliers.
In SPSS viene chiamato vicino limitrofo.
La distanza tra due gruppi è data dalla mediana delle distanze tra gli elementi di un gruppo e dell’altro.
E' il metodo dei centroidi pesati che dà lo stesso ad ogni gruppo cosicché le entità nei cluster più piccoli, di fatto, pesino di più.
In SPSS viene chiamato clustering mediana.
La distanza tra due gruppi è data dalla distanza tra i centroidi, cioè dai valori medi calcolati sulle unità appartenenti ai singoli gruppi.
Si applica solo a variabili quantitative e lavora non tanto sulla matrice delle distanze quanto sui singoli vettori di osservazioni. Ignora le dimensioni del cluster da aggregare.
In SPSS è chiamato clustering baricentro.
Al contrario del metodo aggregativo, quello divisivo segue l’approccio top-down ossia partendo dal dataset completo e dividendolo in partizioni fino a che non si raggiunga una condizione prestabilita che la maggior parte delle volte coincide con il numero di cluster fissato.
Il metodo divisivo è più complesso rispetto a quello agglomerativo perché si basa sull’esecuzione di subroutine che permettono di suddividere il data points iniziale. In alcuni casi risulta anche essere più efficiente nel senso che il metodo divisivo converge più velocemente rispetto a quello aggregativo.
Inoltre, l’algoritmo divisivo è più accurato perché tiene conto della distribuzione globale dei dati per creare le prime partizioni

Nella cluster analysis non gerarchica il numero di gruppi in cui suddividere il campione viene deciso a priori e sono disponibili diverse tecniche per questa tipologia di analisi.
La più diffusa è l’algoritmo k means o delle k medie in italiano, e consiste nel creare k gruppi e calcolarne il centroide o punto medio. Nota che questo metodo si può utilizzare solo per variabili quantitative.
Nel caso della cluster analysis gerarchica, come già accennato, è necessario guardare il dendrogramma per capire quanti gruppi formare. Ad esempio, nel grafico qui sotto la linea rossa sta a indicare i taglio che bisogna fare per ottenere 3 gruppi che corrispondono alle linee che interseca.
Si decide di prendere 3 cluster perchè per le loro aggregazioni bisogna "percorrere" molta strada nel senso che se si volesse ulteriormente aggregare tra di loro quei tre cluster bisognerebbe fare uno sforzo maggiore perchè le linee si congiungono troppo in avanti.

Nel caso della cluster analysis non gerarchica bisogna osservare le medie dei gruppi e dare un nome agli stessi. Di solito una rappresentazione con il grafico radar rende meglio l’idea. Attento che al concetto di media aritmetica va sempre associato quello di deviazione standard.
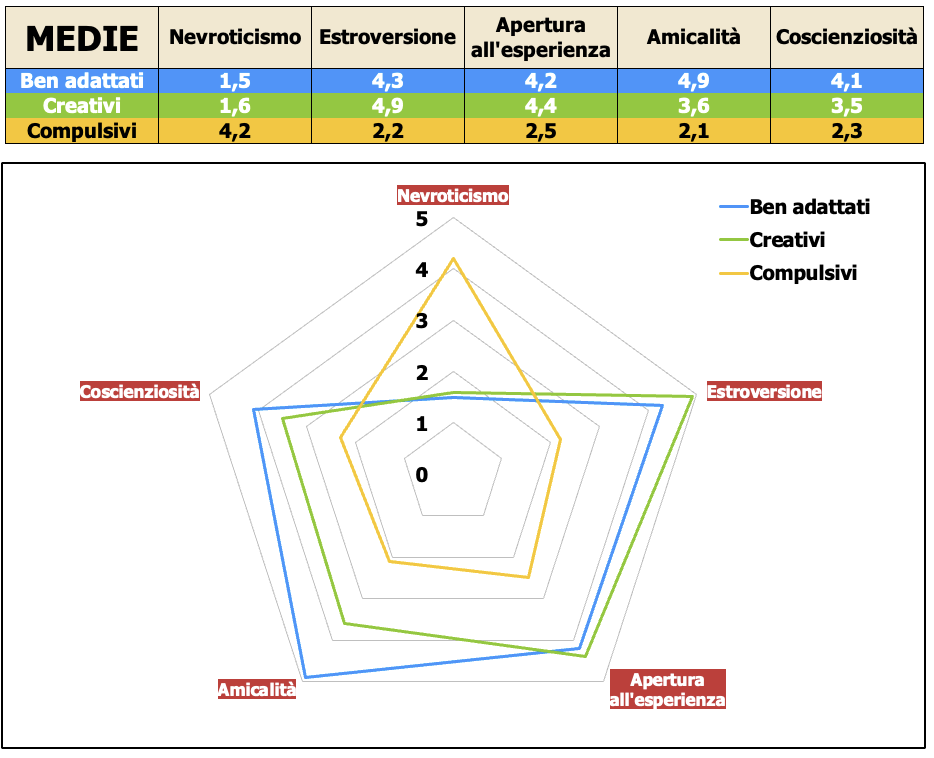

Quando ti approccerai al software per condurre la cluster analysis, io uso SPSS, noterai che spesso si trova posizionata vicino all'analisi discriminante. Questo perchè entrambe riguardano la suddivisione di diversi dati statistici in gruppi omogenei, però sono due tecniche con obiettivi molto diversi.
La cluster analysis, come abbiamo visto, ha lo scopo di suddividere le osservazioni contenute nel dataset in gruppi, mentre l’analisi discriminante si utilizza per i dati presenti in classi distinte, e per assegnare poi nuove osservazioni in uno dei gruppi che hai precedentemente definito.
Quindi, benchè le due tecniche possano sembrare simili, in realtà vanno a delineare due diverse aree di analisi.
I maggiori software statistici come SPSS e R permettono di condurre la cluster analysis usando le diverse tecniche di clustering viste sopra. Qui di seguito ti mostro i comandi da usare.
Non c’è un comando
Analizza >>> Riduzione delle dimensioni >>> Cluster…
Il modo in cui una squadra gioca nel suo complesso determina il successo. Si può avere un gruppo formato dalle migliori stelle del mondo, ma se non giocano bene insieme, la squadra non varrà un centesimo.
(BABE RUTH, Giocatore di baseball statunitense)
Iscriviti alla Newsletter