

blog

Partiamo dal dire che ANOVA è l’acronimo di Analysis of Variance, cioè l’analisi della varianza, quella tecnica statistica che ti permette di verificare se c’è relazione tra una o più variabili dipendenti quantitative e una o più variabili indipendenti qualitative.
Nella statistica inferenziale ci sono tanti test d'ipotesi che comprendono l'ANOVA la quale si divide poi in diverse tipologie: scegliere quale utilizzare dipende da quante e quali sono le variabili che prendi in considerazione, e anche se sono indipendenti (le cause) o dipendenti (gli effetti).

Vediamo insieme questi diversi tipi:
Si dice ANOVA a una via proprio perché la variabile indipendente, o fattore, è unica. Se invece le variabili indipendenti sono due o più si parlerà, rispettivamente, di ANOVA a due vie o ANOVA fattoriale.
L’ANOVA a una via si utilizza quando vuoi verificare se c’è differenza tra le medie tra gruppi. Questi gruppi possono avere due o più modalità ed lì la distinzione tra le due tecniche statistiche:
L'ANOVA a una via è dunque una generalizzazione del t-test a campioni indipendenti e questa relazione la noti proprio quando fai il TEST-F dell'ANOVA il quale risulterà sempre il quadrato del TEST-T nel caso in cui i gruppi siano due.
Se i gruppi sono due vuol dire che la variabile qualitativa è dicotomica.
Un esempio pratico può essere quello di dover confrontare la spesa di prodotti alimentari (variabile quantitativa) tra maschi e femmine (variabile qualitativa dicotomica).
In questo caso, l'ANOVA a una via produce lo stesso risultato di un t-test a campioni indipendenti in termini di significatività (p-value), ma come detto con il test F che sarà il quadrato del test T.
Se i gruppi sono più di due allora puoi usare solo l'ANOVA a una via e non il test t per campioni indipendenti.
Ad esempio, immagina di voler confrontare la spesa di prodotti alimentari tra le aree geografiche italiane (nord, centro, sud)
Ti lascio qua sotto un mio video tratto dalla playlist delle metafore statistiche che ti fa capire bene il significato del test t a campioni indipendenti.

Ma perché si parla di analisi della varianza quando, di fatto, si analizza le differenza tra medie? Perchè si osserva appunto quanto variano le medie tra di loro.
Per confrontare due gruppi occorre calcolare la loro media e la loro varianza. Il confronto però non si esaurisce lì, ma come sempre accade nell'inferenza statistica c'è bisogno di eseguire un test d'ipotesi per determinare la relazione tra le variabili.
Per farlo devi scomporre la varianza totale della variabile dipendente in due parti chiamate varianza entro i gruppi, o within-group, e varianza tra i gruppi, between-group.
La varianza entro i gruppi è dovuta alle differenze all’interno di ogni singolo gruppo, mentre la varianza tra i gruppi si riferisce alle differenze tra gruppi stessi. Quest’ultima è quella che viene studiata dal TEST F dell'ANOVA a una via.
Se la seconda prevale sulla prima allora molto probabilmente ci sarà una differenza tra le medie dei gruppi che darà luogo a un p-value inferiore a 0,05 e quindi significativo, potendo dunque affermare che esiste una relazione tra i due fenomeni

Questa scomposizione della varianza dunque ti permette di capire se la differenza tra le medie dei gruppi sia causata dalla variazione tra gruppi oppure sia effetto delle differenze tra le singole osservazioni e le medie di ogni gruppo.
Prima di spiegarti come calcolare un’ANOVA a una via ti elenco quali sono le assunzioni che devono essere soddisfatte per condurre questo tipo di analisi:
É richiesto che la variabile numerica analizzata nei vari gruppi abbia una distribuzione normale, soprattutto nel caso di campioni di piccole dimensioni.

L'omoschedasticità è la verifica dell’ipotesi che le varianze nei differenti gruppi siano uguali. All'interno di un'anova a una via la verifica avviene con un test di Levene per l’omogeneità delle varianze. Lo schema di ipotesi è:
Se il p-value di tale test è minore di 0,05 le varianze dei gruppi sono statisticamente diverse tra loro, e quindi devi fare molta attenzione prima di trarre conclusioni affrettate circa la differenza tra le medie di tali gruppi.

Le unità statistiche devono essere indipendenti, altrimenti potrebbero generare dei bias cognitivi. Sebbene sia un argomento trattato in psicologia, i bias sono molto presenti negli studi statistici perchè influenzano certamente i risultati.
A tal proposito ho voluto dedicare una playlist completa su questa interessante sfumatura raggruppando ben 166 bias!
166 bias cognitivi spiegati in modo semplice con degli short
Fai attenzione: se applichi l’ANOVA a una via quando almeno una delle tre assunzioni qui sopra è violata, potresti ottenere un risultato del test sovrastimato, che ti invalida l’analisi!
Ci sono comunque situazioni in cui il modello lineare è robusto oppure puoi scegliere l'alternativa di un test non parametrico che nel caso dell'ANOVA a una via è il test di Kruskal-Wallis.

Per eseguire un’ANOVA a una via sono necessari diversi calcoli che, per fortuna, i maggiori software statistici, come SPSS, eseguono autonomamente. Qui di seguito voglio mostrarti i passaggi necessari per arrivare al TEST F dell'ANOVA a una via.
La base da cui partire è questo schema che puoi trovare insieme a tutti i formulari di statistica scaricando la mia guida gratuita su come superare un esame di statistica

Supponiamo di avere i dati relativi agli stipendi di un gruppo di lavoratori che appartiene a un'azienda che ha tre sedi in Europa.
La seguente tabella mostra la distribuzione dei salari e il numero di persone in ciascuna categoria:
\[
\begin{array}{|c|c|c|c|c|}
\hline
\textbf{X = Origine} & 500-1500 & 1500-2500 & 2500-3500 & \textbf{Totale} \\
\hline
\text{Italia} & 168 & 28 & 4 & 200 \\
\hline
\text{Francia} & 78 & 80 & 42 & 200 \\
\hline
\text{Germania} & 60 & 96 & 44 & 200 \\
\hline
\textbf{Totale} & 306 & 204 & 90 & 600 \\
\hline
\end{array}
\]
Calcolo della media generale:
\[
\mu_Y = \frac{\sum y_j n_j}{N}
\]
\[
\mu_Y = \frac{(1000 \times 306) + (2000 \times 204) + (3000 \times 90)}{600} = 1640
\]
Calcolo della varianza totale:
\[
\text{Var}(Y) = \frac{\sum y_j^2 n_j}{N} - \mu_Y^2
\]
\[
\text{Var}(Y) = \frac{(1000^2 \times 306) + (2000^2 \times 204) + (3000^2 \times 90)}{600} - 1640^2
\]
\[
\text{Var}(Y) = 530.400
\]
Calcolo delle medie condizionate per gruppo:
Per Italia:
\[
\mu_{Y|X_1} = \frac{(1000 \times 168) + (2000 \times 28) + (3000 \times 4)}{200} = 1180
\]
Per Francia:
\[
\mu_{Y|X_2} = \frac{(1000 \times 78) + (2000 \times 80) + (3000 \times 42)}{200} = 1820
\]
Per Germania:
\[
\mu_{Y|X_3} = \frac{(1000 \times 60) + (2000 \times 96) + (3000 \times 44)}{200} = 1920
\]
Calcolo delle varianze all'interno dei gruppi:
Per Italia:
\[
\text{Var}(Y|X_1) = \frac{(1000^2 \times 168) + (2000^2 \times 28) + (3000^2 \times 4)}{200} - 1180^2
\]
\[
\text{Var}(Y|X_1) = 187.600
\]
Per Francia:
\[
\text{Var}(Y|X_2) = \frac{(1000^2 \times 78) + (2000^2 \times 80) + (3000^2 \times 42)}{200} - 1820^2
\]
\[
\text{Var}(Y|X_2) = 567.600
\]
Per Germania:
\[
\text{Var}(Y|X_3) = \frac{(1000^2 \times 60) + (2000^2 \times 96) + (3000^2 \times 44)}{200} - 1920^2
\]
\[
\text{Var}(Y|X_3) = 513.600
\]
Calcolo della varianza fra gruppi:
\[
\text{Var}_{\text{FRA}} = \frac{(1180^2 \times 200) + (1820^2 \times 200) + (1920^2 \times 200)}{600} - 1640^2
\]
\[
\text{Var}_{\text{FRA}} = 107.466,7
\]
Calcolo della varianza nei gruppi:
\[
\text{Var}_{\text{NEI}} = \frac{(187.600 \times 200) + (567.600 \times 200) + (513.600 \times 200)}{600}
\]
\[
\text{Var}_{\text{NEI}} = 422.933,3
\]
Verifica della scomposizione della varianza:
\[
\text{Var}(Y) = \text{Var}_{\text{FRA}} + \text{Var}_{\text{NEI}}
\]
\[
530.400 = 107.466,7 + 422.933,3
\]
Schema riassuntivo finale:
\[
\begin{array}{|c|c|c|c|}
\hline
\textbf{Tipologia} & \mu_{Y|X} & \text{Var}(Y|X) & n_i \\
\hline
\text{Italia} & 1180 & 187.600 & 200 \\
\hline
\text{Francia} & 1820 & 567.600 & 200 \\
\hline
\text{Germania} & 1920 & 513.600 & 200 \\
\hline
\end{array}
\]
\[
\begin{array}{|c|c|}
\hline
\textbf{Varianza} & \textbf{Valore} \\
\hline
\text{Varianza tra gruppi } (\text{Var}_{\text{FRA}}) & 107.466,7 \\
\hline
\text{Varianza nei gruppi } (\text{Var}_{\text{NEI}}) & 422.933,3 \\
\hline
\text{Varianza totale } (\text{Var}(Y)) & 530.400 \\
\hline
\end{array}
\]
Conclusione:
Abbiamo scomposto la varianza totale in due componenti:
Se stai preparando un esame universitario sappi che grazie alla calcolatrice scientifica SHARP puoi fare questi calcoli in modo pratico e veloce. Guarda il video che ho realizzato.


Se ti fermassi al punto precedente potresti esser fuorviato dal fatto che la varianza nei gruppi è risultata superiore a quelli tra gruppi e quindi vorrebbe dire che la differenza tra medie è dovuta più alla variabilità interna che esterna.
La differenza tra il reddito degli italiani, 1920 euro, e quello degli stranieri, 1180 euro, è però notevole. Allora come facciamo a stabilire se questa differenza è significativa? Beh ovviamente con un test d'ipotesi.
Le ipotesi del test F dell'ANOVA a una via sono:
La statistica test che si utilizza per sancire tali ipotesi è la distribuzione di Fisher-Snedecor, detta anche distribuzione F. Questa non è altro che il rapporto tra la varianza tra i gruppi e quella entro i gruppi:
F = [Devb / (k-1)] / [Devw / (n-k)]
Maggiore è la varianza between (quella al numeratore) rispetto a quella within (quella al denominatore), maggiore sarà il valore di F, e di conseguenza è più probabile che si arriverà al rifiuto dell’ipotesi H0.
Adesso hai bisogno del valore critico della distribuzione di Fisher che delineano le regioni di rifiuto e di accettazione delle ipotesi. Lo trovi nella corrispondente tavola statistica, di cui ti mostro qui sotto uno stralcio. Il valore lo trovi incrociando i gradi di libertà del numeratore, k-1, con quelli del denominatore, n-k.
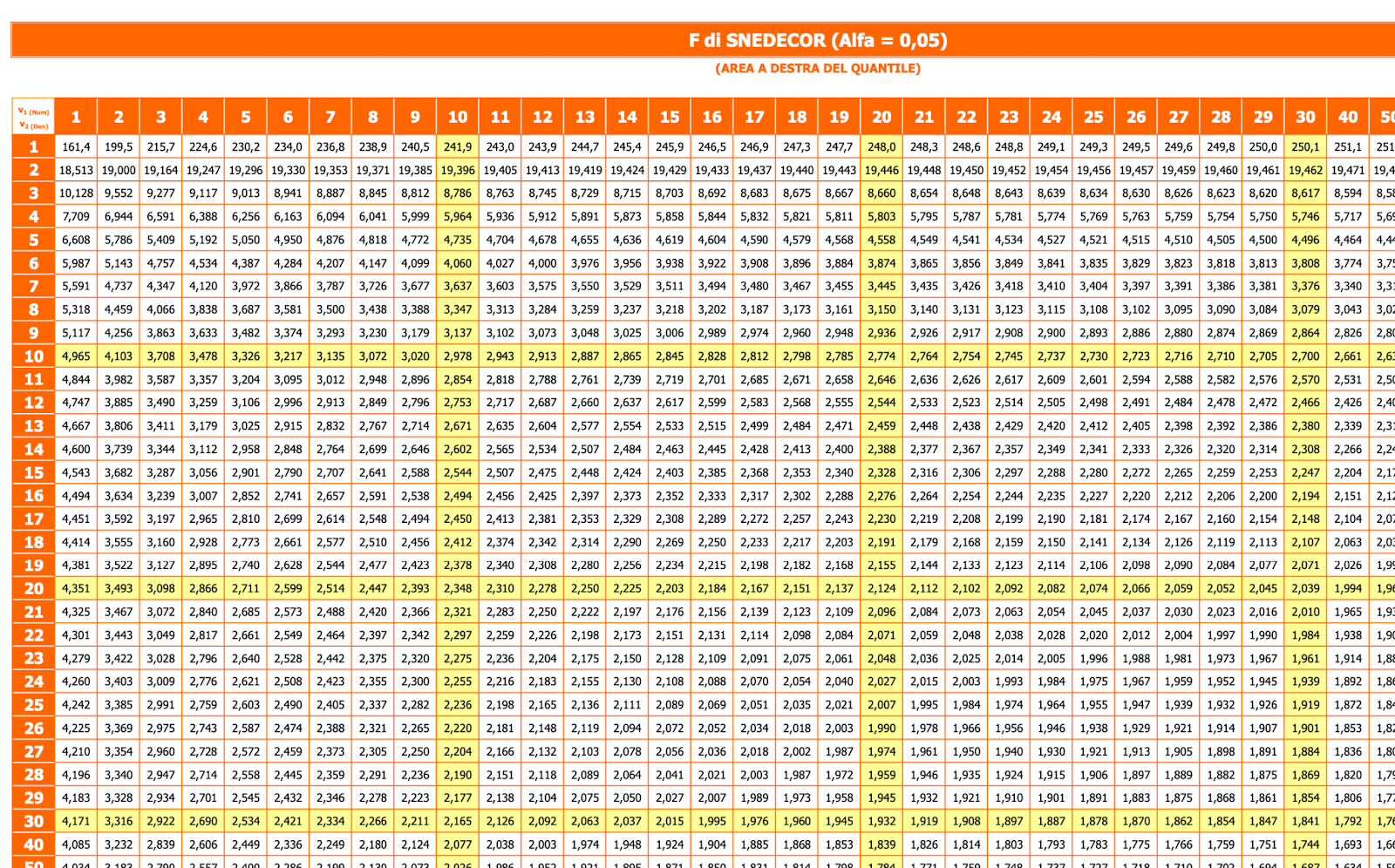
Fissato un livello di significatività 𝛼 e calcolato quindi il valore critico F𝛼(k-1,n-k) puoi ricadere in uno dei seguenti casi:
Un metodo alternativo per stabilire se accettare o rifiutare H0 è quello del p-value:
Se non sei sicuro di che cosa sia il p-value, guarda questo video in cui te lo spiego in modo chiaro e semplice utilizzando una metafora statistica.
Riprendiamo l'esercizio sopra e ricordando che nella tabella dell'ANOVA a una via si parte dalle somma dei quadrati che non è altro che la DEVIANZA, cioè la varianza moltiplicata per il numero di osservazioni N.
Tabella ANOVA a una via:
\[
\begin{array}{|c|c|c|c|c|c|}
\hline
\scriptsize\textbf{Varianza} & \scriptsize\textbf{Somma Quad} & \scriptsize\textbf{df} & \scriptsize\textbf{Media Quad (MS)} & \scriptsize\textbf{F} & \scriptsize\textbf{Sig.} \\
\hline
\scriptsize\text{FRA gruppi (Between)} & \scriptsize64.480.020 & \scriptsize2 & \scriptsize32.240.010 & \scriptsize75,8 & \scriptsize< 0,0001 \\
\hline
\scriptsize\text{NEI gruppi (Within)} & \scriptsize253.759.980 & \scriptsize597 & \scriptsize425.083 & & \\
\hline
\scriptsize\text{TOTALE} & \scriptsize318.240.000 & \scriptsize599 & & & \\
\hline
\end{array}
\]
Calcolo del test F:
\[
F = \frac{MS_{\text{fra}}}{MS_{\text{nei}}}
\]
\[
F = \frac{32.240.010}{425.083} = 75,8
\]
Confronto con il valore critico:
Il valore critico \(F_{\alpha}(2, 597)\) per un livello di significatività del 5% è circa 3,02.
\[
F_{test} = 75,8 > F_{critico} = 3,02
\]
Poiché il valore del test-F è molto maggiore di quello critico, rifiutiamo l'ipotesi nulla, indicando una differenza significativa tra i gruppi.
Per concludere ti lascio un video introduttivo nel quale ti spiego come tratterò l'ANOVA all'interno del mio video corso sull'analisi dati con SPSS.

Per scopi di ricerca o professionali in cui è necessario approfondire l’analisi, non basta calcolare l'ANOVA a una via, ma si devono effettuare i cosiddetti test a posteriori o test post-hoc.
Questi test ha senso eseguirli quando i gruppi della variabile categoriale sono almeno tre in quanto si tratta di confronti a due a due e non avrebbe senso con solo due gruppi.
Nel caso in cui il test F risultasse significativo (e quindi almeno uno dei gruppi differisce dagli altri) i test post-hoc ti consentono di verificare quali tra le medie dei livelli del fattore between differiscono tra loro.
I test post-hoc utilizzano procedure specifiche per controllare il tasso di errore di Tipo I, ossia la probabilità di trovare una differenza significativa quando non esiste.
Questo è importante perché fare molteplici confronti senza controllare il tasso di errore aumenta la probabilità di ottenere falsi positivi.
Questi test effettuano un confronto multiplo tra tutti i gruppi presenti, identificando i sottogruppi omogenei. I test post-hoc più utilizzati sono il test HSD di Tukey e il test di Bonferroni, ma ne esistono altri tipi, i quali, la maggior parte delle volte restituiscono risultati analoghi.

Il test di Tukey HSD (Honest Significant Difference) confronta tutte le possibili coppie di gruppi per identificare quali differiscono significativamente.
È un test conservativo, in quanto il suo errore di I tipo non varia al variare del numero di confronti effettuati.
È ideale per confronti multipli quando si ha un numero simile di osservazioni per ciascun gruppo e il numero dei gruppi è basso ( J < 5 ).
Il test di Tukey HSD utilizza la distribuzione studentizzata delle range per calcolare la differenza minima significativa tra le medie dei gruppi. La formula per la differenza minima significativa (HSD) è:
\(\displaystyle \text{HSD} = q \sqrt{\frac{MSE}{n}} \)
Dove:
1 - Eseguire l'ANOVA a una via: verificare se ci sono differenze significative tra le medie dei gruppi.
2 - Derivare il MSE dai risultati dell'ANOVA a una via.
3 - Determinare il valore critico q: utilizzare tavole specifiche o software statistici per trovare il valore di q appropriato.
4 - Calcolare il Test HSD: applicare la formula sopra per trovare la differenza minima significativa.
5 - Confrontare le medie dei gruppi: calcolare le differenze tra tutte le coppie di medie dei gruppi e confrontarle con l'HSD. Se la differenza tra le medie è maggiore dell'HSD, allora la differenza è significativa.
Calcolo dell'HSD:
\[
HSD = 3,34 \times \sqrt{\frac{425.083}{200}}
\]
\[
HSD = 3,34 \times \sqrt{2125,42}
\]
\[
HSD = 3,34 \times 46,09 = 153,97
\]
Confronto tra le differenze delle medie:
\[
|\mu_{Italia} - \mu_{Francia}| = |1180 - 1820| = 640
\]
\[
|\mu_{Italia} - \mu_{Germania}| = |1180 - 1920| = 740
\]
\[
|\mu_{Francia} - \mu_{Germania}| = |1820 - 1920| = 100
\]
Interpretazione:
Il valore critico HSD è 153,97. Confrontando le differenze tra le medie:
Poiché due delle tre differenze sono superiori al valore HSD, possiamo concludere che "Italia e Francia" e "Italia e Germania" presentano differenze significative, mentre "Francia e Germania" non differiscono in modo significativo.
Il test post-hoc di Bonferroni è una tecnica utilizzata nell'analisi statistica per affrontare il problema delle comparazioni multiple.
Quando conduciamo più test statistici simultaneamente, aumenta la probabilità di ottenere risultati statisticamente significativi per caso, anche se non esistono reali differenze.
Questo è noto come errore di tipo I o falso positivo. Il test di Bonferroni aiuta a controllare questo errore riducendo il rischio di falsi positivi, ovvero errori di Tipo I.
È un test conservativo adatto per le ricerche esplorative.
In particolare la diseguaglianza di Bonferroni dimostra che la probabilità che almeno un test sia significativo è minore o uguale alla somma delle probabilità che ogni test sia significativo.
αe < kα, dove k = numero di test effettuati.
La correzione di Bonferroni si basa sulla divisione del livello di significatività α per il numero totale di test k. Se il livello di significatività iniziale è α = 0,05 e stai conducendo test, la soglia di significatività corretta sarà 0,05 / k.
Il numero di k test che si possono effettuare è uguale alla formula J * ( J - 1 ) / 2, dove J è il numero dei gruppi della variabile qualitativa
Esempio:
α = 0,05
J = 4 gruppi
k = ( 4 * 3 ) / 2 = 6 test
soglia corretta = 0,05 / 6 = 0,0083
In alternativa tutti i principali software moltiplicano i p-value dei confronti a due a due per il numero k test dimodochè si possa confrontare il p-value con la soglia alfa prestabilita.
Esempio:
α = 0,05
J = 4 gruppi
k = 6 test
p-value gruppo 1 vs gruppo 2 = 0,03
p-value reale = 0,03 * 6 = 0,18
Risultato del test: Non posso rifiutare H0 perchè p > α ( 0,18 > 0,05)
1 - Eseguire l'ANOVA a una via: verificare se ci sono differenze significative tra le medie dei gruppi.
2 - Calcolare i p-value: eseguire i test statistici individuali e ottenere i p-value per ciascuno.
3 - Correggere i p-value: dividere ogni p-value per il numero totale di test k. Alternativamente, si può confrontare ogni p-value originale con α / k.
4 - Confrontare con il livello di significatività: se un p-value corretto è inferiore a α / k, si rifiuta l'ipotesi nulla per quel test specifico.
Formula per il test di Bonferroni:
\[
t = \frac{|\mu_i - \mu_j|}{\sqrt{\frac{2 MSE}{n}}}
\]
Dove:
Calcolo del valore test:
\[
t_{Italia-Francia} = \frac{|1180 - 1820|}{\sqrt{\frac{2 \times 425.083}{200}}} = \frac{640}{\sqrt{4250,83}} = \frac{640}{65,2} = 9,82
\]
\[
t_{Italia-Germania} = \frac{|1180 - 1920|}{\sqrt{\frac{2 \times 425.083}{200}}} = \frac{740}{65,2} = 11,35
\]
\[
t_{Francia-Germania} = \frac{|1820 - 1920|}{\sqrt{\frac{2 \times 425.083}{200}}} = \frac{100}{65,2} = 1,53
\]
Calcolo del p-value corretto con Bonferroni:
Per ottenere il p-value, confrontiamo il valore test con la distribuzione t di Student con i 597 gradi di libertà e moltiplichiamo per il numero di confronti \( C \) per applicare la correzione di Bonferroni:
\[
p_{\text{corretto}} = p_{\text{non corretto}} \times C
\]
Con \( C = \frac{k (k - 1)}{2} = \frac{3 (3 - 1)}{2} = 3 \) confronti possibili:
Interpretazione:
Dopo la correzione di Bonferroni:
Questo significa che Italia ha salari significativamente diversi da entrambi gli altri gruppi, mentre Francia e Germania non mostrano una differenza statisticamente significativa dopo la correzione per confronti multipli.
Il test S-N-K (Student-Newman-Keuls) ordina le medie e poi procede a confrontarle, partendo dalle coppie di medie più vicine fino a quelle più distanti.
Il test S-N-K è spesso scelto per la sua capacità di bilanciare potenza statistica e controllo degli errori.
Il motivo principale per cui viene utilizzato è che consente un'analisi dettagliata e graduale delle differenze tra le medie dei gruppi, confrontando inizialmente le medie più vicine e procedendo verso quelle più distanti.
Questo approccio progressivo è utile per identificare pattern specifici nelle differenze tra i gruppi, il che può essere meno evidente con altri test post-hoc.
É più liberale quando i confronti stimati sono pochi ( < 5 ), ma diventa più conservativo all'aumentare dei confronti.
l test S-N-K utilizza una statistica basata sulla differenza tra le medie dei gruppi e la distribuzione studentizzata delle range. La formula per il confronto tra due medie è:
\(\displaystyle
q = \frac{\left| \bar{X}_i - \bar{X}_j \right|}{\sqrt{MSE \left( \frac{2}{n} \right) }}
\)
Dove:
Il valore critico per \( q \) viene determinato in base alla distribuzione studentizzata delle range e dipende dal livello di significatività \( \alpha \), dal numero di gruppi e dai gradi di libertà dell'errore.
1 - Eseguire l'ANOVA a una via: verificare se ci sono differenze significative tra le medie dei gruppi.
2 - Derivare il MSE dai risultati dell'ANOVA.
3 - Ordinare le medie dei gruppi in ordine crescente
4 - Calcolare la statistica q per ogni confronto: utilizzare la formula sopra per calcolare il valore q per ciascuna coppia di medie.
5 - Confrontare con il valore critico q: Utilizzare tavole specifiche o software statistici per trovare il valore critico q per il livello di significatività desiderato, il numero di gruppi e i gradi di libertà dell'errore.
Ordinamento delle medie:
\[
{Germania (1920) > Francia (1820) > Italia (1180)}
\]
Calcolo delle differenze tra le medie:
\[
{Germania - Italia} = 1920 - 1180 = 740
\]
\[
{Francia - Italia} = 1820 - 1180 = 640
\]
\[
{Germania - Francia} = 1920 - 1820 = 100
\]
Calcolo dell'Errore Standard:
\[
SE = \sqrt{\frac{2 \cdot MSE}{n}}
\]
\[
SE = \sqrt{\frac{2 \times 425058.6}{200}} = \sqrt{4250.586} \approx 65.20
\]
Ricerca dei valori di Studentized Range (q):
Dato che abbiamo 3 gruppi (\( k = 3 \)) e 597 gradi di libertà, cerchiamo i valori di \( q \) (Studentized Range) a un livello di significatività di 0.05:
\[
q(0.05, 3, 597) \approx 3.31 \quad ( {3 passi})
\]
\[
q(0.05, 2, 597) \approx 2.77 \quad ( {2 passi})
\]
Calcolo della Differenza Minima Significativa (MDS):
\[
MDS (3 { passi}) = 3.31 \times 65.20 \approx 215.80
\]
\[
MDS (2 { passi}) = 2.77 \times 65.20 \approx 180.60
\]
Confronto delle differenze osservate con la MDS:
Il test post-hoc R-E-G-W-Q (Ryan-Einot-Gabriel-Welsch-Studentized Range Q) modifica il test S-N-K utilizzando sempre la statistica q, calcolando il valore p di ogni confronto sulla base del range r tra le medie confrontate, ma corregge anche il valore p utilizzando la formula pc = 1 -( 1 - p )k/r
Il test R-E-G-W-Q offre un buon compromesso tra la potenza statistica e il controllo degli errori di tipo I (falsi positivi).
È meno conservativo rispetto al test di Bonferroni, il che significa che ha una maggiore probabilità di rilevare differenze reali, ma è più conservativo rispetto al test di Tukey, il che aiuta a ridurre la probabilità di falsi positivi.
É particolarmente efficace quando i gruppi hanno dimensioni diverse ed è il test che consiglio di utilizzare se non si hanno motivi particolari.
Utilizza quello che è noto come approccio step-down per controllare l'errore familywise. In questo test, non vengono calcolati intervalli di confidenza.
Il test R-E-G-W-Q utilizza una procedura iterativa che combina la distribuzione F e la distribuzione studentizzata delle range. La differenza minima significativa (HSD) viene calcolata in modo simile al test HSD di Tukey, ma con adattamenti per tenere conto delle diverse dimensioni dei gruppi.
La formula per la differenza minima significativa tra due medie è:
\(\displaystyle
q = \frac{\left| \bar{X}_i - \bar{X}_j \right|}{\sqrt{MSE \left( \frac{1}{n_i} + \frac{1}{n_j} \right) }}
\)
Dove:
1 - Eseguire l'ANOVA a una via: verificare se ci sono differenze significative tra le medie dei gruppi.
2 - Derivare il MSE dai risultati dell'ANOVA.
3 - Ordinare le medie dei gruppi in ordine crescente
4 - Calcolare la statistica q per ogni confronto: utilizzare la formula sopra per calcolare il valore q per ciascuna coppia di medie.
5 - Confrontare con il valore critico q: Utilizzare tavole specifiche o software statistici per trovare il valore critico q per il livello di significatività desiderato, il numero di gruppi e i gradi di libertà dell'errore.
6 - Calcolare l'HSD: applicare la formula sopra per trovare la differenza minima significativa.
7 - Confrontare le medie dei gruppi: Calcolare le differenze tra tutte le coppie di medie dei gruppi e confrontarle con l'HSD. Se la differenza tra le medie è maggiore dell'HSD, allora la differenza è significativa.
Ordinamento delle medie:
\[
\text{Germania (1920) > Francia (1820) > Italia (1180)}
\]
Calcolo delle differenze tra le medie:
\[
\text{Germania - Italia} = 1920 - 1180 = 740
\]
\[
\text{Francia - Italia} = 1820 - 1180 = 640
\]
\[
\text{Germania - Francia} = 1920 - 1820 = 100
\]
Calcolo dell'Errore Standard:
\[
SE = \sqrt{\frac{2 \cdot MSE}{n}}
\]
\[
SE = \sqrt{\frac{2 \times 425083}{200}} = \sqrt{4250.83} \approx 65.20
\]
Ricerca dei valori di Studentized Range (q):
Dato che abbiamo 3 gruppi (\( k = 3 \)) e 597 gradi di libertà, cerchiamo i valori di \( q \) (Studentized Range) a un livello di significatività di 0.05:
\[
q(0.05, 3, 597) \approx 3.40 \quad (\text{3 passi})
\]
\[
q(0.05, 2, 597) \approx 2.85 \quad (\text{2 passi})
\]
Calcolo della Differenza Minima Significativa (MDS):
\[
MDS (\text{3 passi}) = 3.40 \times 65.20 \approx 221.68
\]
\[
MDS (\text{2 passi}) = 2.85 \times 65.20 \approx 185.82
\]
Confronto delle differenze osservate con la MDS:

Scheda dati >>> Analisi dati >>> Analisi varianza: ad un fattore
Analizza >>> Confronta medie >>> Medie
Analizza >>> Confronta medie >>> Anova univariata
Analizza >>> Modello lineare generalizzato >>> Univariata



Il governo è molto arguto nell’ammassare grandi quantità di statistiche. Le colleziona, le somma, le eleva all’ennesima potenza, ne estrae la radice quadrata e prepara impressionanti diagrammi. Ciò che non si deve mai dimenticare, comunque, è che in ogni caso le cifre vengono in prima istanza redatte dal guardiano del villaggio, che tira fuori ciò che diavolo gli pare e piace.
(Josiah Stamp, scrittore, economista, banchiere, industriale e statista inglese).
Iscriviti alla Newsletter